

微信人工投票平台 人工智能化、深度学习、深度神经网络究竟都是啥?

实际上微信人工投票平台,将来初创公司的商业计划书很容易猜到:选用“X AI”方式,X能够是一切一个领域或是情景。即在合适的行业添加线上智能化,让其持续稳步发展。Kevin Kelly《必然》
以往两年,人工智能化一直是最热点话题之一。高层次人才竞相参加人工智能化科学研究,知名企业会拨出去高额资产适用该行业发展趋势,而人工智能化初创公司每一年能够得到 数十亿美元的项目投资。
假如你已经考虑到改善工作流程,或已经寻找新的念头微博人工刷票,那麼很可能会想起人工智能化。为了更好地更高效率地应用人工智能化,必须深入了解其构成部分。

人工智能化
人工智能化究竟是什么?Keras鼻祖、Google人工智能化研究者Francois Chollet在其书《Python深度学习》(Deep Learning with Python)中得出了一个简洁明了的界定:“人们根据努力创造智力活动的自动化技术。因而,人工智能化是一个包含深度学习和深度神经网络的通用性行业,也包含很多不涉及到一切学习方法。”
比如,现如今对话机器人的原名Eliza是由麻省理工大学人工智能化试验室造就的。这一程序流程能够和人们开展长期会话,但不可以在会话中学习培训新英语单词或改正个人行为。Eliza的个人行为是根据一种独特的计算机语言确立制订的。
当代实际意义上的人工智能化起源于二十世纪50年代,莱纳•图灵(Alan Turing)和达特茅斯讨论会(Dartmouth workshop)将这一行业的第一批发烧友集聚在一起,从而产生了人工智能科学的基本概念。除此之外,在变成当今社会科学研究重要行业的全过程中,人工智能化产业链经历了数次兴趣爱好猛增和衰落(也就是说白了的“人工智能化的冬季”)。
值得一提的是强人工智能化和弱人工智能化的假定。强人工智能化能够思索,并可以像一个单独的人一样有着观念。弱人工智能化则沒有这种工作能力,只有实行一定范畴内的每日任务(下象棋、识别图像中的猫或画一张市场价43.25万美金的画)。现阶段现有的都归属于弱人工智能化,还无须过度担忧。
现如今,离去人工智能化,人们基本上举步维艰。不论是驾车、自拍照、网上买东西還是分配休闲度假,基本上到处都能发觉人工智能化的存有。这类存有非常容易被忽视,却十分关键。
深度学习
无论是人工智能化还是是非非人工智能化,其重要特点是学习培训的工作能力。对人工智能化来讲,有一系列深度学习实体模型承担塑造这类工作能力。其实质与经典算法不一样。经典算法是一组清楚的命令,能将键入的数据交换成結果,而深度学习根据数据信息样版和相对結果,在数据信息中发觉方式并形成一种优化算法,可以将随意数据交换成所需的結果。
深度学习关键分成三类:
无监督学习——系统软件以已经知道結果的数据信息样版为基本,对每一个样版开展训炼。深度学习有二种每日任务更为受欢迎:重归 (regression)和归类(classification)。重归对于连续型自变量,例如楼价或加工制造业排污水准。归类则是对某一类其他预测分析。比如,一封电子邮件是不是归属于垃圾短信,某一本书归属于侦探小说還是百科辞典这些。
无监督学习——系统软件自身发觉数据信息內部的关联和方式。在这里状况下,每一个样版的結果全是不明的。
增强学习——一种奖赏系统软件恰当个人行为,处罚系统软件错误做法的方式。因而,系统软件学会了开发设计某类优化算法,能够获得最大的奖赏和最少的处罚。
一个理想化的深度学习实体模型能够剖析一切数据信息,寻找全部的方式,并建立优化算法以完成全部期待获得的結果。但这一理想化的实体模型并未创建。加州大学专家教授Pedro Domingos在其经典著作《主算法》(The Master Algorithm)中就有讲到其建立全过程。
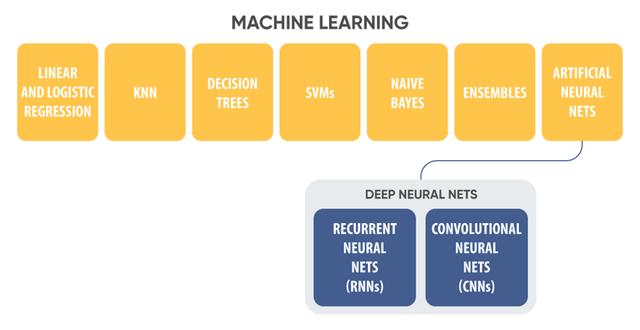
现如今的深度学习实体模型致力于特殊的每日任务,都是有分别的优点和缺点。这种实体模型包含:
线性回归(Linear regression)是一种經典的统计模型。说白了,它是为重归每日任务设计方案的,即能够用于预测分析持续值。比如,柠檬汁的销售量高矮在于气温的优劣。
逻辑回归(Logistic regression)用以归类每日任务微信人工投票平台,预测分析给出样版归属于特殊类型的几率。
决策树算法(Decision Tree)是一种常见的分类方法。在这类方式中,给出目标的类型依据一系列难题的回应来明确。每一难题的回答一般为“是”或“否”。
K近期邻(k-Nearest Neighbor,KNN)随机森林算法是一种简易、迅速的分类方法。在这类方式中,假如一个样版在特点室内空间中的k(个k能够为随意值)最类似(即特点室内空间中最相邻)的样版中的大部分归属于某一个类型,则该样版也归属于这一类型。
朴素贝叶斯(Naive Bayes)是一种时兴的分类方法。它运用摡率论和贝叶斯定理来明确某一恶性事件(某一电子邮件为垃圾短信)在给出标准下的概率(电子邮件中20次出現“无息贷款”等语汇)。
svm算法(Support Vector machines) 通称SVM微博人工刷票,是一种监管深度学习优化算法,常见于归类每日任务。即便 每一个目标中间有很多互相关系的特点,它也可以合理分离出来不一样类型的目标。
集成学习(Ensembles)融合了很多深度学习实体模型,并依据“投票法”微博人工刷票,即极少数听从大部分,或将結果平均化,进而明确目标类型。
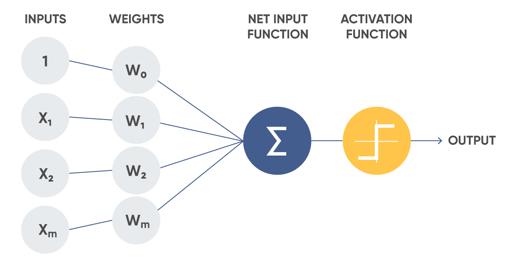
神经元网络(Neural networks)是以人的大脑的基本原理为基本的。神经元网络由很多互相联络的神经细胞构成。神经细胞能够表明为具备好几个键入和一个輸出的涵数。每一个神经细胞从键入中获得主要参数(每一个键入的不一样权重值决策了其关键水平),对其实行特殊作用,并将結果輸出。一个神经细胞的輸出能够是另一个神经细胞的键入。因而,双层神经元网络得到产生。它是深度神经网络的主题风格。以后将对这个问题开展详尽探讨。
神经元结构图:
含双层掩藏层的人工神经元网络:
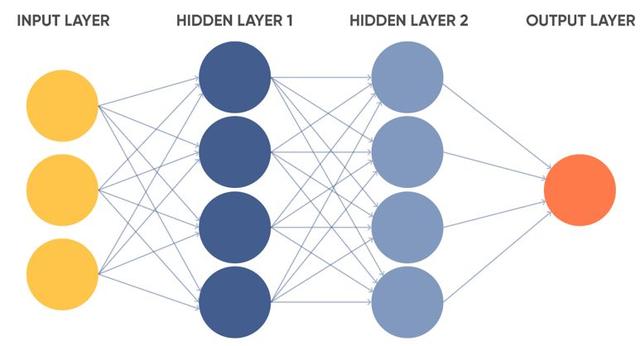
根据科学研究给出样版微信人工投票平台,神经元网络调节神经细胞中间的权重值,使对预期成果危害较大 的神经细胞得到 较大 的权重值。比如,假如一个小动物是花纹的,毛绒绒的,会喵喵叫,那麼它很可能是一只猫。另外,大家将较大 权重值赋给“会喵喵叫”这一主要参数。因此 ,假如这只小动物沒有花纹,也不是毛绒绒的,但会喵喵叫——它依然很可能是一只猫。
深度神经网络
深度神经网络牵涉到深层神经元网络。有关深层的见解各不相同。一些权威专家觉得,有两个或之上掩藏层的神经元网络,就可以被觉得是深层的;而另一些权威专家则觉得,仅有有着好几个掩藏层的神经元网络,才能够被觉得是深层的。
如今早已有一些不一样种类的神经元网络获得了积极主动的运用。在其中最火爆的有:
长短期记忆互联网(LSTM)用以文本分类和形成、语音识别技术、创作歌曲和时间序列分析预测分析。
卷积和神经元网络(CNN)用以图像识别技术、视频采集和自然语言理解解决每日任务。
结果
那麼,人工智能化、深度学习和深度神经网络中间有什么不同呢?坚信根据阅读文章本文,你早已拥有回答。人工智能化是智能化每日任务自动化技术的一个普遍行业(如阅读文章、下围棋、图像识别技术和修建无人驾驶轿车);深度学习是一套人工智能化方式,承担塑造人工智能化的自学能力;深度神经网络则归属于科学研究双层神经元网络的深度学习方式。

留言板留言 关注 关心
我们一起共享AI学习培训与发展趋势的干货知识
编译程序组:徐梦瑶、杨敏迎
有关连接:
https://www.kdnuggets.com/2019/08/artificial-intelligence-vs-machine-learning-vs-deep-learning-difference.html#p#分页标题#e#
如需转截,请后台管理留言板留言,遵循转截标准